Excel to R: Do you Like Green Eggs and Ham?
Excel is such a handy tool for data discovery and analysis that it’s fair to ask, “Why bother with anything else, especially an arcane scripting environment like R?” The truth is that the transition from Excel to R is very much a green eggs and ham experience: decidedly unappealing at the outset, even for adventurous folk, but rewarding in the long run. This post takes another look at the Titanic data set, this time using R to do the same analysis done last time in Excel.

As before, the starting point is making readable text from the raw, coded data shown above on the left. R provides a simple substitution function that simply specifies the filter conditions for the variable values to be changed and does a simple replacement. For example, converting the Class codes to the form used in the  summary table takes four statements shown here.
summary table takes four statements shown here.
Following a similar pattern Age and Gender codes become readable text as well. So far, so good. Easy.
The first real hurdle is getting R to present something that looks like a Pivot table, summarizing both the On Board and Survivor data by Class, Gender and Age. Of the several ways that R provides for tabulating data the one that makes the most intuitive sense to Excel users is probably the ‘cast’ function. This is similar to a Pivot table in that it aggregates the values of a selected variable and arranges them in a table based on the values of two descriptive variables.
 Running the tabulation twice (once with the full on-board manifest and once on a subset containing just the survivors) yields the two summaries shown here. Applying a similar treatment using Class and Gender as the descriptive variables and adding a little bit of formatting gives this summary:
Running the tabulation twice (once with the full on-board manifest and once on a subset containing just the survivors) yields the two summaries shown here. Applying a similar treatment using Class and Gender as the descriptive variables and adding a little bit of formatting gives this summary:

It isn’t quite as pretty as the tabulation in Excel but the effort to crunch the numbers in R is about the same. The bonus with R was that it kept track of everything I did in a history file. By the time the job was done I had both the required output and the raw material to start building a repeatable script.
Turning to the passenger manifest downloaded from Kaggle things get a little more interesting. As before, the first objective is to identify family groupings, looking for evidence that the size of group travelling together influenced survival. Since some R functions are fussy about missing values (and the passenger data contains plenty of them) we begin by reading in the two raw CSV files, called “train” and “test”, combining them to a single data set and then standardizing empty values with “NA” as a placeholder:

Family groupings are defined as a unique combination of surname and ticket number. Since names are recorded as “Last Name, Title. First Name”, the following command adds a new feature to the data set called “Surname”. Family size is then calculated as the sum of the two columns for Parent-Child and Sibling-Spouse, assigning 1 when these values add up to zero:
For filtering purposes another new feature categorizes the age data into “Adult” versus “Child” using 18 years as the separation point. The original data table has grown by three variables, enabling creation of a unique family identifier that combines surname, ticket and family size:
![]()
From here invoking the “ggplot2” package plots the entire data set in the form of a histogram that shows survival by family size.

The R command to generate the chart looks like this.

An Excel user learning R doesn’t take very long to discover built-in capabilities to do things that are notoriously difficult in Excel. A case in point would be a box-plot: anyone who has tried it in Excel knows that it can be done but only with considerable time and effort. The ggplot2 package, used above, provides a single-command presentation of a set of box-plots showing fares by class and port of embarkation:
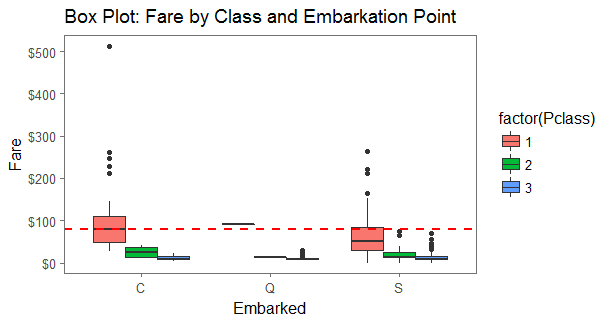

And so the pattern goes: working with R means breaking the analysis into a series of tasks, invoking the appropriate package and constructing a short sequence of commands that complete the task.
One of the tasks in this analysis is assigning ages to passengers with no recorded age. In Excel, that required assumptions about the demographic make-up of the passenger population and a fair bit of data manipulation. R provides a more elegant treatment using the MICE package, which imputes random values for missing ages based on patterns observed in other variables in the data set. Once MICE has been loaded as a library, the following script assigns the missing ages and then produces side-by-side histograms showing that the treatment didn’t change the shape of the age distribution.


With ages assigned a single step renders side-by-side histograms showing survival by Age and Gender:


So, why should a die-hard Excel user learn to do analysis with R? After all, R scripting is a fair distance removed from the familiar point and click experience of Excel, and developing proficiency with R takes time, practice and patience. As I see it, there are four good reasons to make the effort:
- R offers richer capabilities than Excel for summarizing and visualizing data, doing statistical analysis, and developing predictive models that are reusable and deployable to others.
- Learning R is no more difficult than learning to write a VBA macro in Excel.
- R is free, open source software written by and for people who use data to understand real-world problems. When faced with a new problem, chances are there is already a package out there that cover the critical steps.
- The R community is global, and it includes people who are constantly improving the tool and adding new packages to the repository. It also includes ordinary users like Megan Risdal at Kaggle who are happy to share what they know.
None of which is a case for abandoning Excel, which remains just as handy as it ever was. But R is a very nice addition to the analysis toolkit, well worth the effort.